The Big Data feature of the TotalCAE platform enables clients to create on-demand Apache Spark applications driven from Jupyter to analyze ADAS and other Big Data using languages such as Python and Java. This feature works on top of the existing High Performance Computing (HPC) infrastructure used by CAE or other applications without needing to re-invest in separate infrastructure for Big Data.
The whole process to start analyzing data is just three simple steps
- Create an Apache Spark+Jupyter job in the TotalCAE portal or command line.
- Click the resulting URL for Jupyter TotalCAE prints.
- Start coding in Jupyter like below, this simple Python example calculated Pi via pyspark.
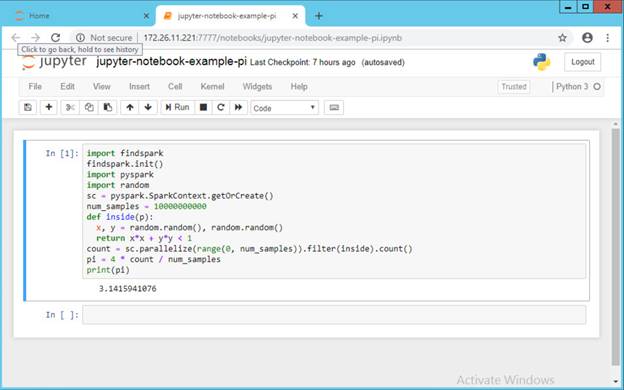
Note that under the hood, TotalCAE has provisioned an Apache Spark cluster dynamically on top of the existing HPC infrastructure, and hooked up Jupyter to the resulting Spark master. When the user is done, they can cancel the job and the Spark cluster will be torn down and the HPC resources returned back for other users to use.
Users can still monitor the provisioned master and workers like they are used to:
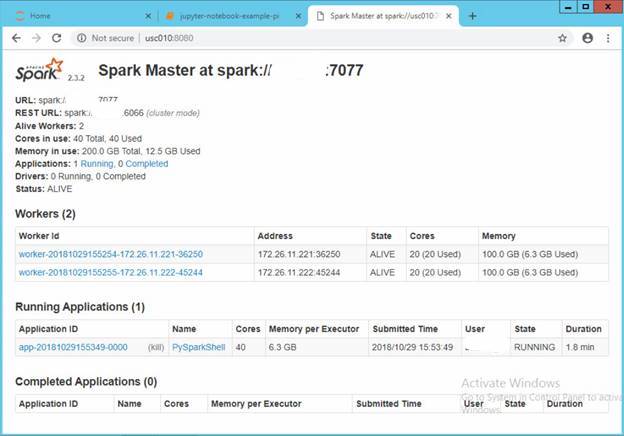
TotalCAE enables clients to leverage their existing on-premise HPC or public cloud investments to explore their emerging big data initiatives such as ADAS with minimal changes to their existing systems.