This week TotalCAE is chairing and facilitating discussions on IT architectures to simplify AI (ML/DL) and ADAS workflows at the Autonomous Vehicles 2019 conference, and this post captures some of our discussions.
Challenges that clients face today with both AI and large scale analytics of ADAS data that we discussed at the workshop include:
- The number of analysis tools grows daily, over 500+ packages with conflicting requirements and frequent updates, which are often a challenge for IT to support, or for scientists to move from their workstation to enterprise production.
- The IT infrastructure for managing an AI environment is often overly complex to operate, upgrade, and use. Often folks try and implement “Google Scale” solutions in-house for container management which leads to overly complex solutions that suck up time and money to manage if you don’t have both “Google Scale” problems and expertise.
- Data management is a key bottleneck, with level 2/3 autonomous cars requiring hundreds of petabytes, and level 5 reported to need Exabytes. Many organizations Data Storage solutions created inflexible storage/compute combos that are difficult to scale and upgrade.
- Some folks wanted to see how to get their company to try and utilize AI that are in more traditional industries, and the challenges of getting business cases approved and funded.
For the first few discussion points, TotalCAE has a turnkey AI appliance solution that breaks up the AI problems into a 4 layer architecture that separates compute, storage, container scheduling, and AI software.
Each stack is simple and standalone, and thus easily to independently migrate, upgrade and operate. Layers can be ran on-premise, cloud, or both. The rest of this post will lightly touch on our AI architecture.
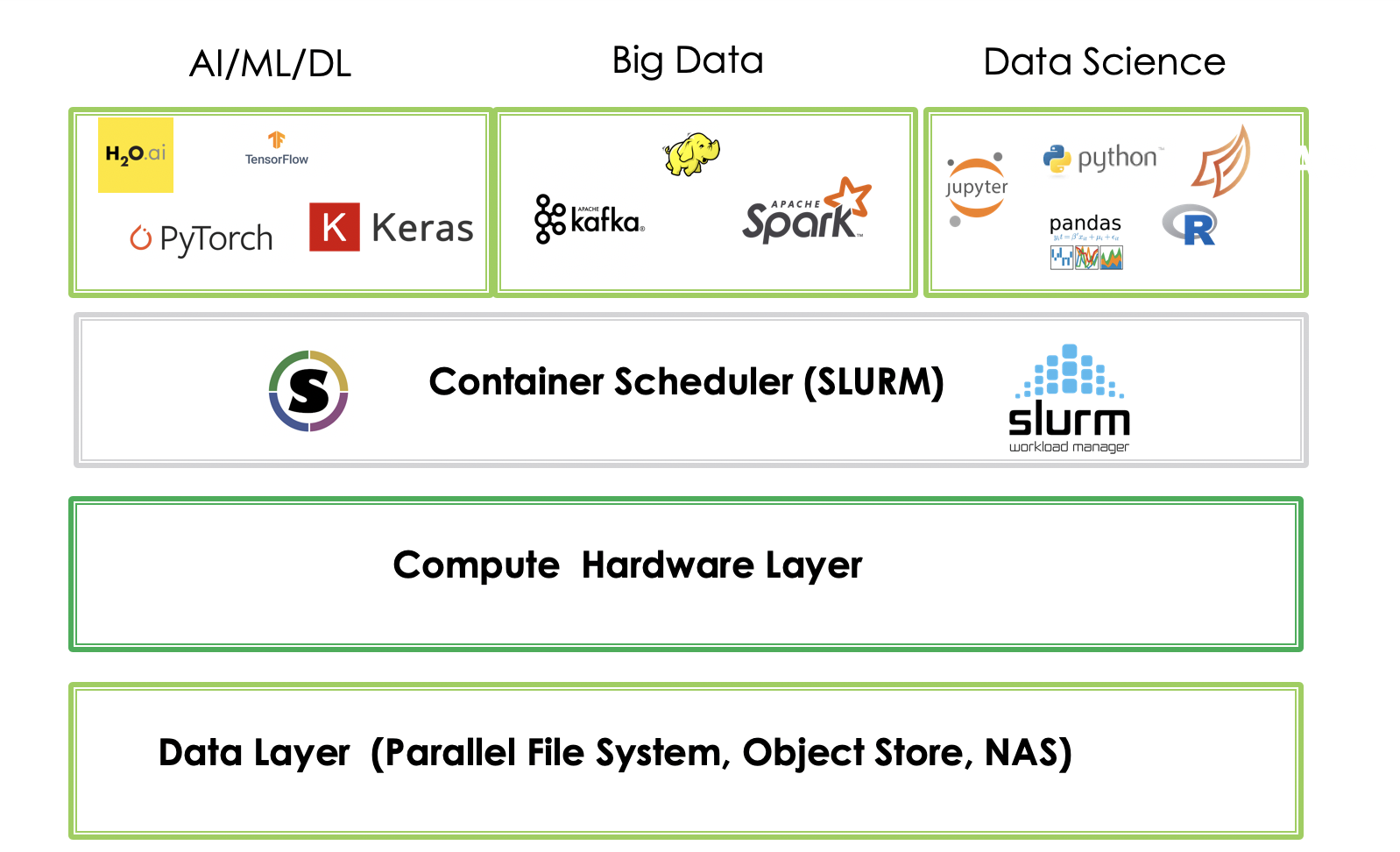
Layer 4. Taming AI application complexity with Singularity containers.
The top level of the stack is the hundreds of AI and Data Science applications utilizing Singularity containers. If you are not familiar with containers, see our post on containers for scientific engineering. Containers can be retrieved from popular software repositories, and can run on-premise or the cloud.
For example, to grab the latest PyTorch from the NVIDIA GPU Accelerated Container Registry is a simple command:
singularity build pytorch3.simg docker://nvcr.io/nvidia/pytorch:19.07-py3
That’s it! You are now ready to run your Pytorch code, as new releases come up you can simply grab the latest container.
Layer 3. Powerfully Simple container scheduling.
Often AI clusters have a mix of NVIDIA compute nodes for production Deep Learning, and standalone compute used for analytics and other tasks. These machines are shared among a group of people, and access is generally done via a HPC scheduler that helps apply business logic and sharing of shared resources amongst groups
For example, the most simplest case of running your PyTorch code on a GPU enabled cluster node is as simple as executing the following line:
srun -p gpu singularity exec –nv pytorch.simg python pytorch.py
which will run your PyTorch code on one of the GPU enabled nodes. Classic HPC schedulers are time tested, simpler to operate, and often better suited to data science workflows.
Layer 2. Compute Hardware
A typical AI cluster has a mixture of computes for Deep Learning with multiple NVIDIA Volta cards per server, login nodes, and a mix of compute nodes. All of this hardware is connected via InfiniBand low latency, high bandwidth network for fast access to shared storage.
Layer 1. Storage
In some Big Data architectures compute and storage are co-mingled, this makes it difficult to scale up just storage, or just compute, decreasing flexibility and increasing operational burden and upgrades. These legacy architectures existed before modern technologies such as 200Gb/s InfiniBand (HDR) , NVMe, and distributed filesystems that can solve the “high speed access to data” without all the complexity.
TotalCAE recommends a separate storage data lake with appropriate scale out architecture that does not require downtime or configuration to add storage, and has sufficient network bandwidth to feed data hungry Deep Learning nodes.
We have worked with several tier-1 suppliers to implement this simple architecture that enabled them to get up to speed on their AI projects. For more information see https://www.totacae.com/ai