TotalCAE recently did a joint webinar with Convergent Science on the performance of their CONVERGE CFD solver to look at the performance impact of 3rd generation Intel Xeon Scalable Processors (Ice Lake). TotalCAE is now shipping 3rd Generation Intel Xeon Scalable Processors with our Managed HPC Cluster Appliance for CONVERGE, and from our select cloud infrastructure partners.
CONVERGE has a nice HPC licensing model that with a “Super-base” license, you can run on an unlimited number of cores per job. For the benchmarking, we fixed the core count using similar clock rated processors, to see the benefits on a core to core basis of these new 3rd generation Intel Xeon Scalable processors.
The benchmark detailed results are available at https://caebench.org
Comparing Intel Xeon 6346 (Ice Lake) to Intel Xeon 6248R (Cascade Lake Refresh) on 32-cores for CONVERGE
Below we ran 32-cores on both processors, and on a per-core basis the Intel Xeon 6346 was 21% faster on this Flame benchmark ( a simulation of the Sandia Flame-D setup, which is a methane burner with ~ 200,000 cells).
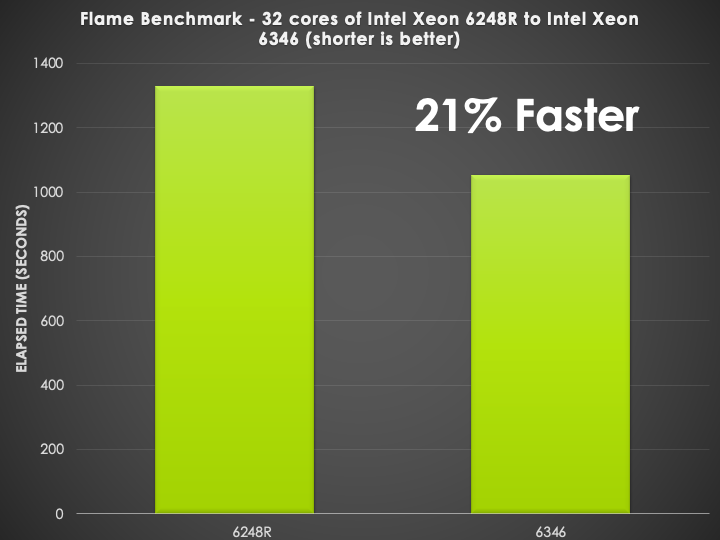
Another H2 engine benchmark was also ran, this is a hydrogen powered internal combustion engine with about 600,000 cells and on 32-cores was about 14% faster than the previous generation Intel processors on a per-core basis.
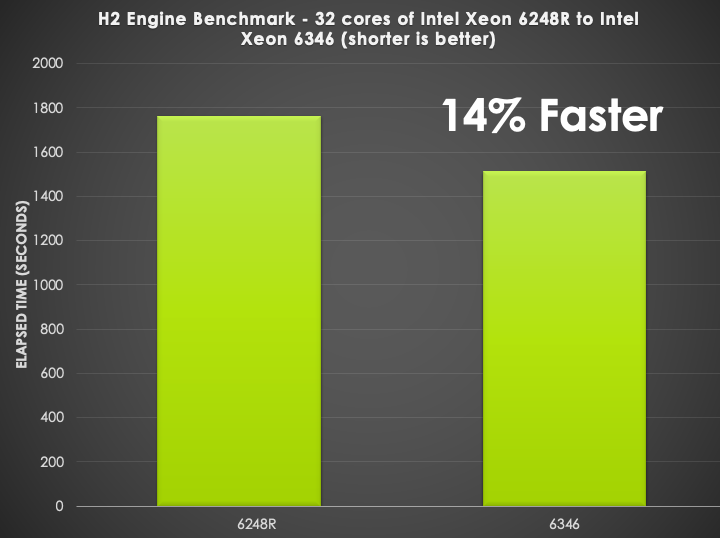
Scaling Benefits of InfiniBand for CONVERGE
We also looked at the impact of HDR InfiniBand on CONVERGE, which scales nicely with increasing core counts as seen below. With the high core count density of todays processors, to achieve large scale out having a low latency interconnect is important for scaling.
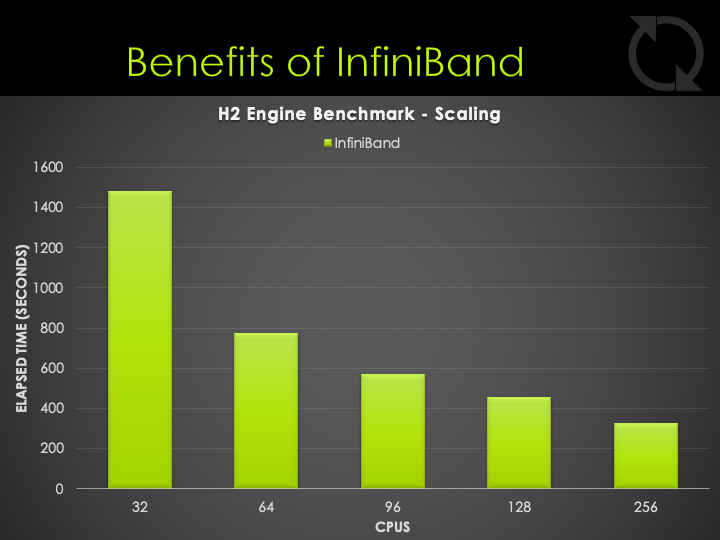
You can see in your CONVERGE simulation the file “mpi_latency.log” that the InfiniBand latency is about 3 microseconds as measured by CONVERGE. On TCP only, this can be hundreds of milliseconds. This low latency of InfiniBand enables CONVERGE to move data between compute nodes quickly, to minimize communication overhead and enable greater scaling. For single node jobs, InfiniBand is not utilized.
mpi_latency.log
# Computed latency from n112 with rank 0 to
# Rank Latency(microseconds) Hostname
32 3.180e+00 #n113
64 3.191e+00 #n114
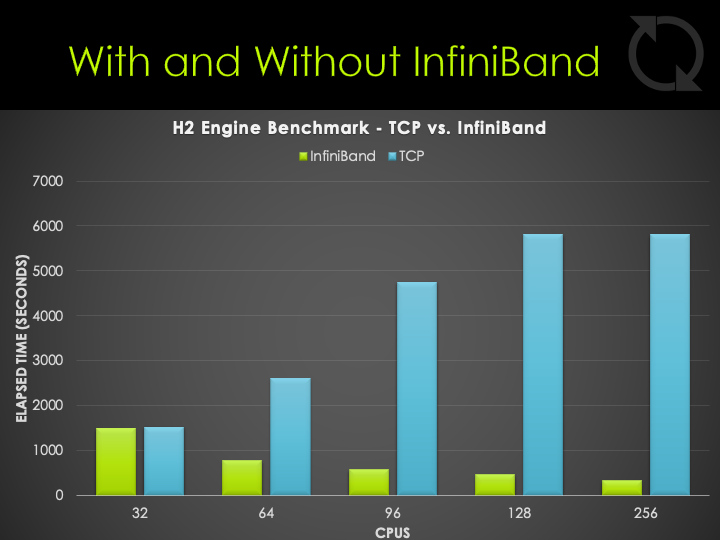
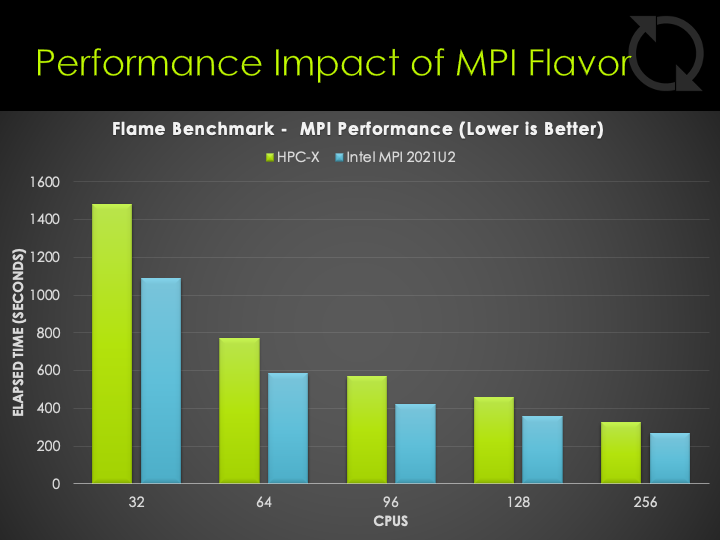
Performance Impact of Chosen MPI Flavor for CONVERGE
CONVERGE ships with several MPI flavors, the TotalCAE Portal enables you to choose between these with a simple dropdown. We did some benchmarking between HPC-X binaries, and the Intel MPI binaries ( using the latest Intel MPI 2021U2 at the time of this writing). The benchmarking showed having a tuned Intel MPI on HDR InfiniBand having an edge in performance, but both MPI flavors performing well.
If you are interested in learning more about TotalCAE managed HPC clusters and cloud for CONVERGE, check out our CONVERGE page at: https://www.totalcae.com/converge