We had a potential client recently testing on their own their CAE applications on AMD EPYC, and were getting poor performance when running on a “stock” out of the box compute node configuration and using all the AMD CPU cores.
But just like racking stock cars, tuning the entire system and application can perform dramatically better than just an out of the box setup.

There are many possible reasons why using a “stock” setup may not perform well for typical CAE applications out of the box on AMD.
AMD EPYC is a More Complex Architecture. AMD EPYC has a novel (and more complex) architecture, this complexity requires a bit more of tuning on the placement of MPI processes to CPU cores out of the box to get performance compared to Intel based systems.
Memory Bandwidth Considerations. It can be counter intuitive to folks that to get good performance on codes that need high memory bandwidth ( like CFD applications) you might get much better performance by strategically using only a small subset of the AMD CPU cores per node to increase memory bandwidth per core. Often people consider the CPU cores they are not using as “wasted”, but the end goal is to accelerate the application and not use every possible core in the memory-bandwidth bound case.
Many CAE applications make extensive use of Intel Math Kernel Library (MKL). Intel MKL is library of highly optimized math routines for Intel Processors many CAE vendors utilize for performance. This library may not be highly tuned to run on non-Intel processors.
Many CAE Applications Utilize Intel AVX512 support. AVX512 can benefit a wide variety of CAE applications and is not available on EPYC (as of Milan), but using AVX enabled binaries if available may narrow the gap.
Applications Often Benefit From Tuning. CAE applications often have many knobs which can improve performance on new architectures.
A Real World Example – Stock vs. Tuned with Abaqus
To give an example, we picked a CAE application (Abaqus) and ran some Abaqus models on a “stock” AMD EPYC Rome, and the latest AMD EPYC Milan configuration on Abaqus 2021 on Linux, often similar to what clients do were they just run it out of the box.
TotalCAE then did some configuration and tuning to drastically decrease the simulation runtime on the AMD EPYC configuration. All runs used 32 CPU cores, and Abaqus 2021.
Tuning Abaqus for AMD EPYC
We performed tuning on various aspects of the system as highlighted below before after gathering the “stock” results.
Intel MPI AMD Tunings, OS Tuning
- Updating the Internal Intel MPI Abaqus uses to take advantage of some new optimized collective operations which we configured.
- Modified how Intel MPI pins processes to cores to optimize for AMD architecture.
- Set OpenMP threads affinity to be optimized for AMD architecture.
- Set the AMD recommended OS tunings.
Abaqus Tunings
We utilized the new Abaqus 2021 Hybrid Message Parallel feature to reduce communication overhead.
Intel MKL Tunings
And for good measure we also tried an unsupported Intel MKL tuning for AMD, but it didn’t have a meaningful impact (< 1%) so it was left as the default.
Results of Benchmarks on Rome and Milan
The first benchmark was a customer benchmark, that benefited from these tunings
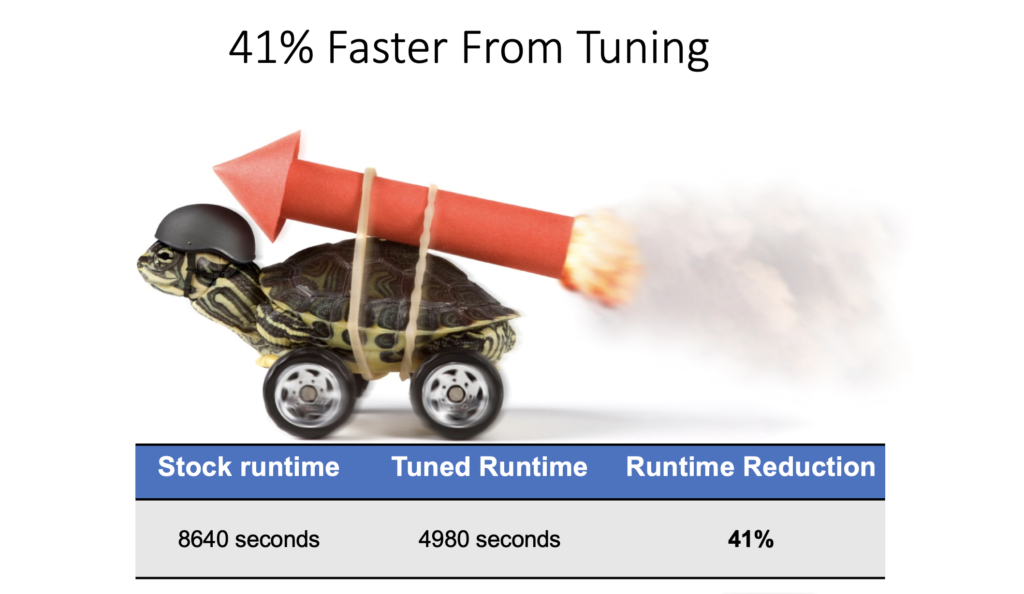
The second is a standard Abaqus model on 32 cores.

Tuning resulted in better performance out of the complete system, compared to just running everything in the stock configuration.
Key Takeaway
AMD EPYC requires some tuning to get performance out of many CAE applications. However complete system tuning of the OS, middleware libraries like MPI, and the application itself can dramatically reduce your runtimes.
TotalCAE systems come with these types of optimizations and recommendations baked in “out of the box” on our managed HPC clusters and managed cloud systems, so you don’t have to be a tuning expert to get performance gains, performance is made simple with TotalCAE.