Sometimes when we engage customers on HPC cluster architectures we get asked about HA (Highly Available) configurations.
Many classical HA configurations are overly complex. Complex configurations lead to complex bugs, complex debugging, and often create more downtime than the rare issue they are trying to guard against. Most catastrophic failures for single points of failure (SPF) are extremely rare.
For customers who need extreme availability we recommend a “multi-island” architecture which eliminates all SPF through a simple architecture that is complexity proof, customer weathered, and time proven.
There are some types of simple redundancy mechanisms that offer a good complexity/benefit tradeoff, such as scheduler failover.
For example, the Slurm scheduler which offers a very simple failover mechanism. The only requirement is that another machine runs a Slurm controller, and that there is a shared state parallel filesystem directory between the two of them.
The diagram below shows this architecture
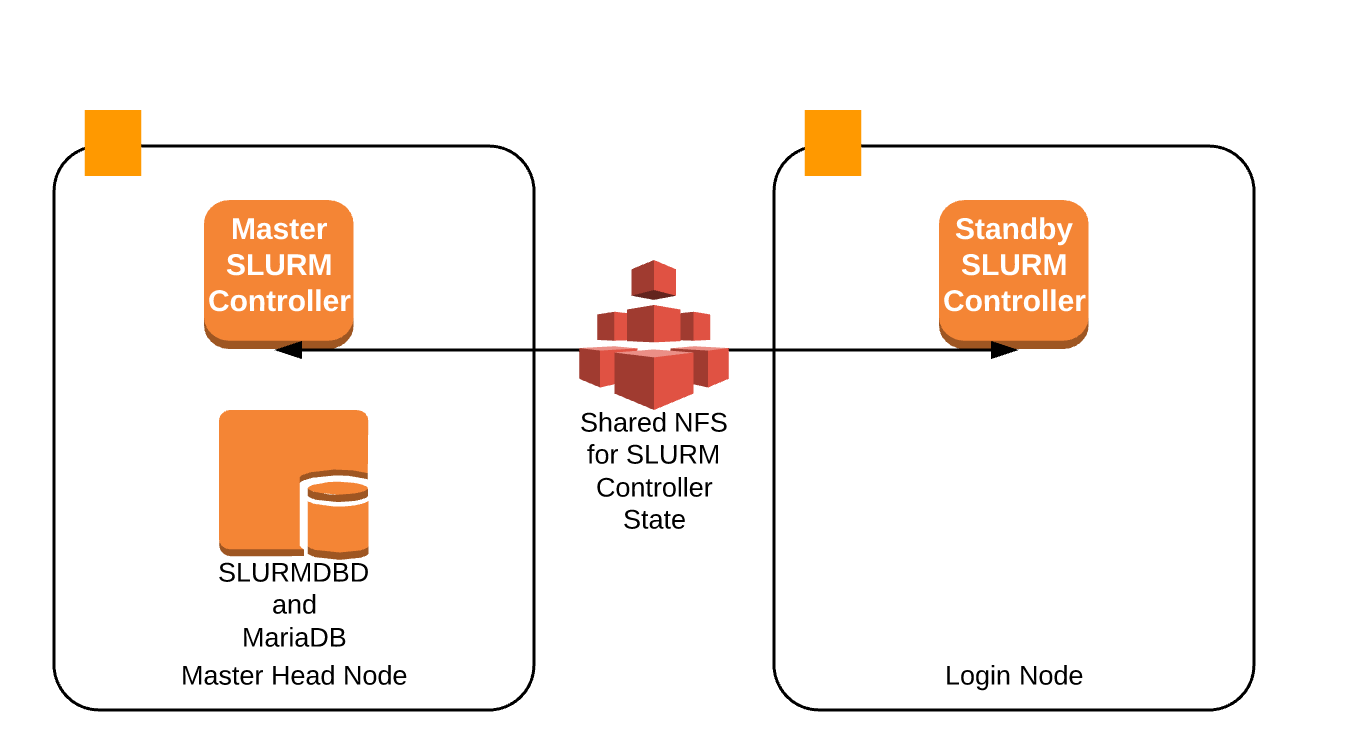
When the primary Slurm controller is unavailable, the backup controller transparently takes over. It queues data, and when the primary head node becomes available, it writes back any needed data and relinquishes control back. HA requires a shared state directory.
The following three settings enable HA in Slurm:
BackupController=[backup name] BackupAddr=[backup address] StateSaveLocation=[shared directory] AccountingStorageBackupHost=[backup name]
The failover is automatic, you can also force a takeover:
scontrol takeover
The Slurm philosophy for HA aligns with the TotalCAE production philosophy we have learned over the last twenty years: to make everything as simple as possible. Simple solutions have fewer and simpler issues, translating to higher uptime and availability.
Note that the StateSaveLocation should be an HPC parallel filesystem mounted on the primary and backup controller, must be highly available, and have a high throughput.
Your environment should be Slurm 23.11 or later, which has some extra protections against there being issues with your StateSaveLocation storage; it has a timestamped marker file that the backup controller will read before taking over.