AWS this week released the latest HPC instance P4, this instance is a beast of a machine with
- Over 1TB of real memory,
- 48 real cpu cores (Intel Xeon Platinum 8275CL @ 3.00 GHz)
- 8TB of local SSD scratch
- Eight of the latest NVIDIA A100 GPU’s A100-SXM4-40GB
- EFA Adapter
At around $32 per node per hour on-demand.
These P4 instances are mainly targeted for AI and ML workloads, but since we are giving a talk next week at the 3DEXPERIENCE conference on speeding up Abaqus with HPC we decided to try out this newest instance with some large Abaqus/Standard models.
The end result was that for the same Abaqus licensing cost, we were able to see a substantial licensing benefit from the latest Intel and NVIDIA technologies that this P4 instance has, over just using CPU’s alone on jobs with 5-8M DOF.
In this case we only used 16 real CPU cores ( HT disabled) and 2 of the A100’s as the sweet spot for licensing and runtime. If in the future there is a lesser P4 instance released (at this time there is one size ( p4d.24xlarge ) , we can right size to that instance.
The real savings is from the NVIDIA card
One nice benefit of GPU’s for Abaqus, is the GPU is treated an extra CPU from a licensing perspective, and so often does not require additional Abaqus tokens. The additional GPUs are giving you essentially “free” speedup, instead of having to throw more CPUs at the problem, which uses substantially more Abaqus licensing.

Monitoring Abaqus GPU Usage with the TotalCAE Platform
TotalCAE platform has tools so you can monitor your Abaqus jobs for a variety of metrics, including how the A100 GPU’s are being utilized to get the best sweet spot for your model
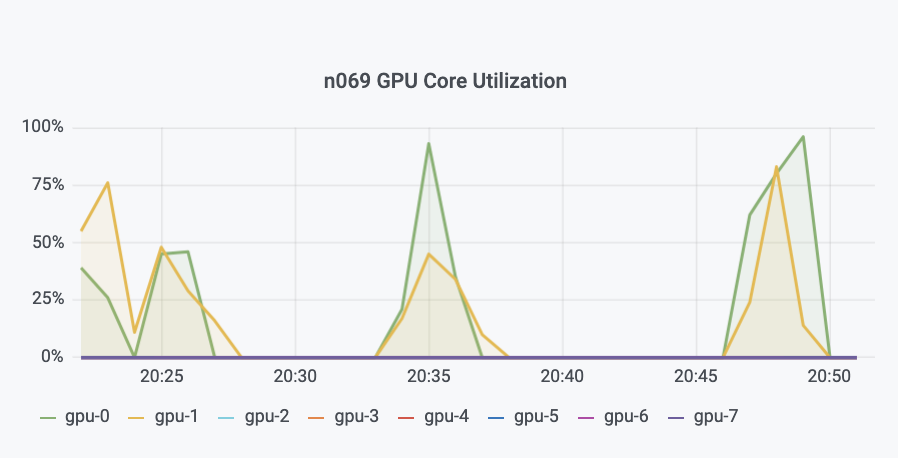
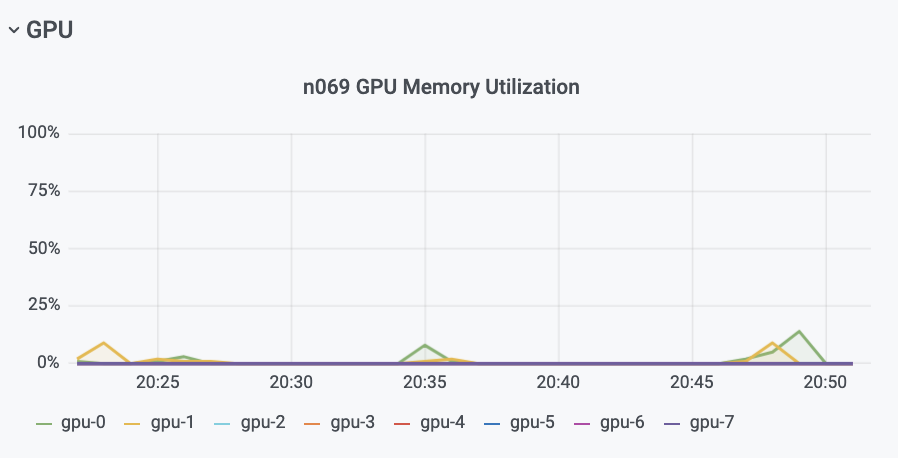
In this case above, we see our Abaqus model is barely touching the GPU memory, but is using a fair amount of GPU cores during the phases that Abaqus offloads the calculations on to the NVIDIA card.
When running too many cards with these models, we see a slow down, and so in this case the 2 x A100 GPU case per MPI process ( even though the machine comes with 8 x A100) was the most optimal to allow the GPU do as much work as possible, avoiding inherit overhead of moving the problem on and off the GPU’s. Anytime there is a new GPU there is some new things that crop up, we see more stability in the NVIDIA V100S with the A100 being very new, but that will work out over time.
If you wanted to check out how easy it is to submit Abaqus jobs to our turnkey HPC on-premise clusters and cloud, check out https://www.totalcae.com/abaqus for more information.